

Photo by Bruno Kelzer on Unsplash
Creating BERT Static Word Embedding Model
and importing into Gensim's KeyedVectors format


Note: BERT is designed for contextual embeddings. Creating static embedding from BERT therefore defeats its purpose.
[1] Install Required Libraries
Ensure that the necessary libraries installed i.e. torch, gensim, numpy, and transformers (Hugging Face's library).
!pip install torch gensim numpy transformers
[2] Load the PreTrained BERT Model
Load the pretrained BERT Model from the library using the from_pretrained method.
from transformers import BertTokenizer, BertModel
model_name = 'bert-base-uncased'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name)
[3] Extract Static Word Embeddings
Extract the static word embeddings from the BERT model.
Iterate over the list of words and pass each word through the BERT tokenizer.
Then, use the BERT model to obtain the corresponding word embeddings.
import numpy as np
import torch
words=['man','queen','london','woman','washington','king']
word_vectors = {}
for word in words:
encoded_input = tokenizer.encode_plus(word, add_special_tokens=True, return_tensors='pt')
with torch.no_grad():
embeddings = model(**encoded_input)[0].numpy()
word_vectors[word] = np.mean(embeddings, axis=1).squeeze()
The encode_plus method tokenizes the word and adds special tokens required by BERT.
The resulting word embeddings are averaged along the sequence dimension to obtain a fixed-size vector for each word.
[4] Save Word Embeddings in Gensim's KeyedVectors Format
Save the word embeddings in the KeyedVectors format using Gensim.
This format allows the embeddings to be loaded and used efficiently.
from gensim.models import KeyedVectors
embedding_size=768
wv = KeyedVectors(vector_size=embedding_size)
wv.add_vectors(list(word_vectors.keys()), list(word_vectors.values()))
wv.save_word2vec_format('bert_static_embeddings_768.bin', binary=True)
In the above code, embedding_size represents the dimensionality of the BERT word embeddings. The add_vectors method adds the word and embedding pairs to the KeyedVectors model, and save_word2vec_format saves the embeddings in the binary format.
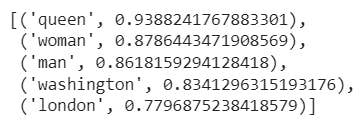
test wv:
# test wv
wv.most_similar('king')
[5] Load Word Embeddings in Gensim's KeyedVectors Format
wv_from_bin = KeyedVectors.load_word2vec_format("bert_static_embeddings_768.bin", binary=True)
wv_from_bin

test wv_from_bin
# test wv_from_bin
wv_from_bin.most_similar('king')

Colab Notebook:
https://colab.research.google.com/drive/1E62blnJpJrgwEOW97RFZqbv2lPfqIw4W?usp=sharing